午安各位!昨天介紹過決策樹跟隨機森林的原理之後,今天我們要來實做這兩個模型。因為昨天有提到這兩種模型可以做不只兩種類別的分類,所以今天我們就跟上次一樣用,用實作SVM的時候那個情感分析的資料集來測試。不過因為要做不只兩類的分析,所以我們把分類成"irrelevant"的資料刪掉就好,然後用正向分數、負向分數跟中壢分數來訓練模型。因為前處理的東西之前都已經帶過了(有需要的人可以回去SVM的實作看看),這邊就直接進入到模型訓練的部分。
我們一樣把scikit learn裡面用來訓練決策樹的套件先引進來再把資料送進去訓練。
from sklearn import tree
dt = tree.DecisionTreeClassifier(max_depth=3, random_state=0)
dt.fit(train_feature[["pos", "neg", "neu"]], clean_train["label"])
決策樹再初始化模型的時候有一個max_depth參數可以讓我們限制樹最多種到第幾層。為了等一下視覺化出來的圖片不要太複雜,這邊我們先設定3層就好。接下來一樣讓訓練好的模型預測一下測試集的資料分類,也用accuracy, presicion, recall, 跟f-score來評估一下它的表現。
from sklearn.metrics import confusion_matrix, precision_recall_fscore_support, accuracy_score
prediction = dt.predict(test_feature[["pos", "neg", "neu"]])
print(confusion_matrix(clean_test["label"], prediction))
evaluation = precision_recall_fscore_support(clean_test["label"], prediction, average='macro')
accuracy = accuracy_score(clean_test["label"], prediction)
print("accuracy: " + str(round(accuracy, 2)) + "\nprecision: " + str(round(evaluation[0], 2)) + "\nrecall: " + str(round(evaluation[1], 2)) + "\nfscore: " + str(round(evaluation[2],2)))
# 輸出
[[215 0 51]
[191 0 94]
[101 0 176]]
accuracy: 0.47
precision: 0.32
recall: 0.48
fscore: 0.38
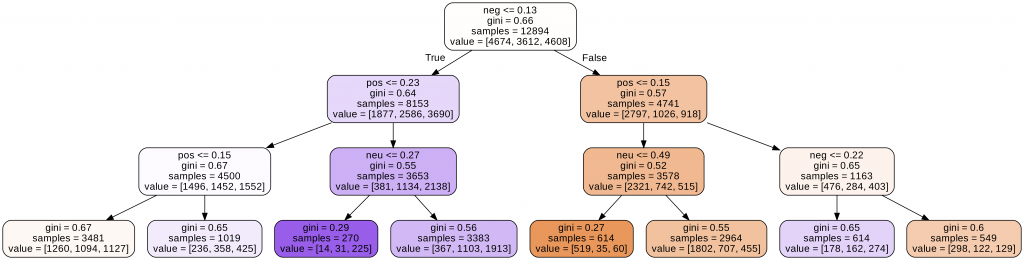
結果真的是慘不忍睹XDD 看來這不是SVM的問題而是資料或特徵選錯的問題了XDD 雖然結果很差,我們還是要看一下它做決策的過程啦,一起把樹畫出來~我們要安裝graphviz這個套件來跟scikit learn合作寫出一個含有樹的dot檔。
!pip install graphviz
from sklearn.tree import export_graphviz
export_graphviz(dt, out_file='tree_decision_classifier.dot',
feature_names = ["pos", "neg", "neu"],
rounded = True, proportion = False,
precision = 2, filled = True)
接著再透過轉檔命令讓它變成可以在python裡面呈現的png檔就可以看到樹啦~!
from subprocess import call
call(['dot', '-Tpng', 'tree_decision_classifier.dot', '-o', 'tree_decision_classifier.png', '-Gdpi=600'])
from IPython.display import Image
Image(filename = 'tree_decision_classifier.png')
https://ithelp.ithome.com.tw/upload/images/20221009/20151687WDFqKNSzbF.png
基本上隨機森林的做法也大同小異啦。已經做到第五種模型了,相信大家應該都明白了,我們先把模型從scikit learn裡面引進來之後初始化它。接著再把訓練集的特徵資料跟正確答案丟進去訓練模型。
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(max_depth=10, random_state=0)
rf.fit(train_feature[["pos", "neg", "neu"]], clean_train["label"])
再來就是讓模型預測測試集裡面資料的分類之後評估它的表現。
rf_prediction = rf.predict(test_feature[["pos", "neg", "neu"]])
print(confusion_matrix(clean_test["label"], rf_prediction))
evaluation = precision_recall_fscore_support(clean_test["label"], rf_prediction, average='macro')
accuracy = accuracy_score(clean_test["label"], rf_prediction)
print("accuracy: " + str(round(accuracy, 2)) + "\nprecision: " + str(round(evaluation[0], 2)) + "\nrecall: " + str(round(evaluation[1], 2)) + "\nfscore: " + str(round(evaluation[2],2)))
我們來看看結果是不是真的比決策樹好
# 輸出
[[176 20 70]
[121 34 130]
[ 51 25 201]]
accuracy: 0.5
precision: 0.48
recall: 0.5
fscore: 0.45
嗯...隨機森林的表現確實比決策樹好,但也是不怎麼樣啦XDD 總之模型訓練的過程就是這麼顛沛流離,不管是資料、特徵還是算法,甚至是前處理不當都會造成模型表現低落。因此我們必須要在這個過程當中不斷地進行調整才能得到比較好的結果。感覺就像是養小孩一樣(?)好啦~到這邊就是監督式機器學習的終點了,明天會開啟深度學習的章節,我會努力理解清楚再盡量清楚地打出來介紹的XDD 明天見~


{kind=link}